I am pleased to announce the general availability of Aerospike Database 7, the newest release of our multi-model, real-time database. Aerospike 7 continues our focus on extracting the full potential of modern server architectures, ensuring maximum performance across all the storage models we support. We provide the flexibility of managing data and indexes all in memory, or with indexes in memory and data held in SSDs (our patented Hybrid Memory Architecture™), or allowing indexes and data to reside entirely on SSDs. Storage models can be selected for each namespace within a cluster, allowing you to match storage models to workloads. Our 7.0 release adds significant efficiencies for in-memory storage enabled by our work to unify our storage engine formats across all our supported storage options.
A unified storage engine format
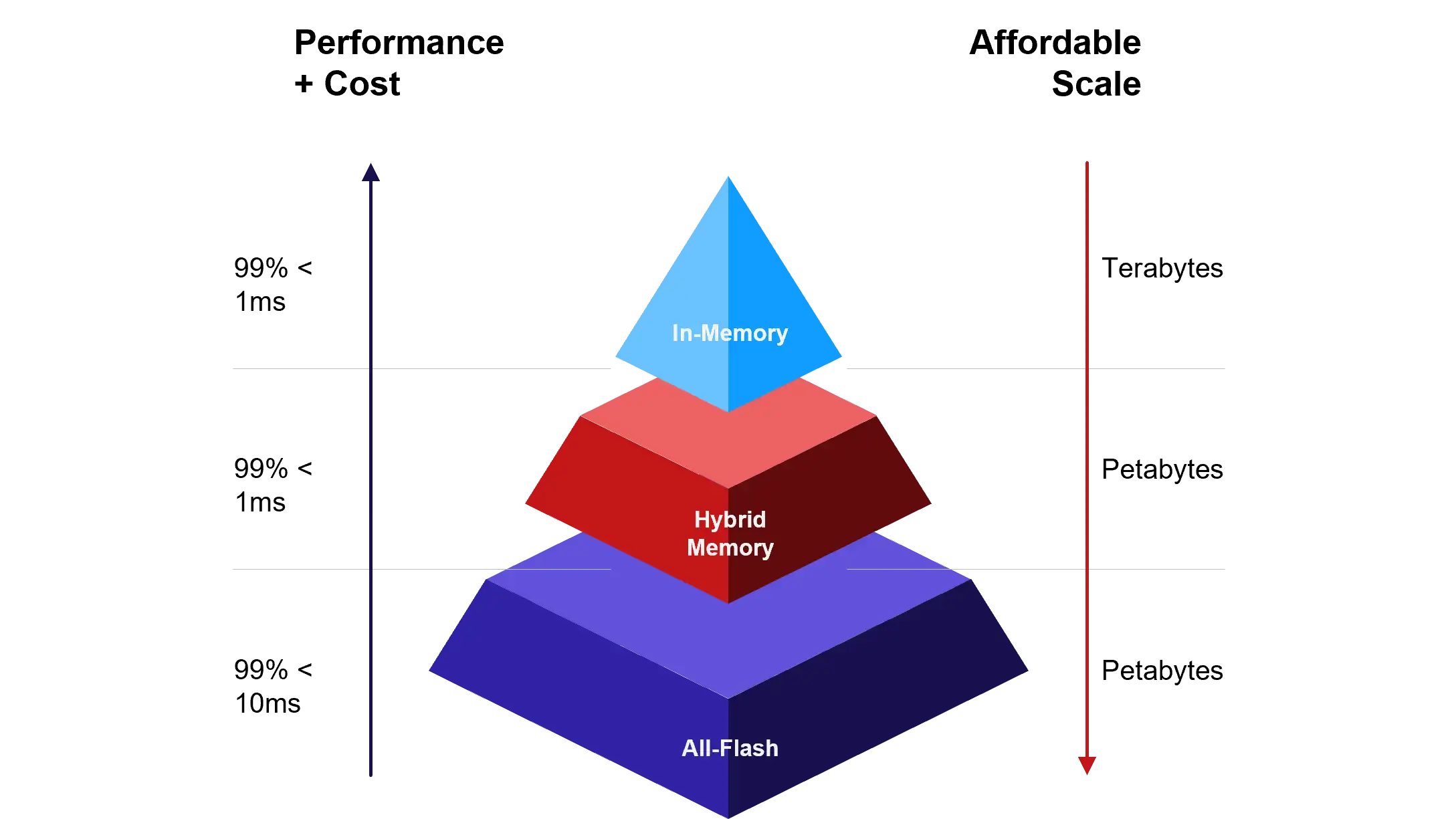
Aerospike has always taken advantage of the unique characteristics of the underlying storage to gain maximum performance with the least amount of hardware. Each storage engine within Aerospike offers the optimal mix of performance and price to meet the unique demands of each workload with enterprise stability, maximum performance, and unlimited scale.
With Aerospike 7, we now have a unified storage format across our three storage engines. This enables new capabilities for handling in-memory workloads, high performance, and efficiency that most specialized in-memory databases could only dream of.
Designing a superior in-memory database
Over the years, we have emphasized the fact that Aerospike is much more than an in-memory database. Most Aerospike implementations utilize our HMA storage engine (indexes in memory, data persisted to SSD), but 30% of Aerospike customers also use Aerospike as an in-memory database. Customers need predictable, sub-millisecond response times for their applications or have existing hardware from a competitive in-memory system migration. Several enhancements that come with the unified storage format significantly strengthen Aerospike 7 as an in-memory database.
Warm restarts
Because the new in-memory storage engine stores its data in shared memory, in-memory namespaces can fast restart upon failing, as the restarted database can simply read data from shared memory instead of retrieving the persisted data from SSD.
In-memory compression
We’ve added the ability to use familiar compression algorithms (e.g., LZ4, Snappy, etc.) on in-memory namespaces, effectively expanding the amount of data that can fit in memory. This saves precious space in DRAM and dramatically lowers costs while delivering ultra-fast performance.
Faster in-memory operations
Because in-memory and on-device storage now use the same storage format, in-memory namespaces are mirrored to their persistence layer. That means database operations, such as defrag, garbage collection, and tomb-raiding, are performed in memory and are therefore much faster.
All this makes for a superior in-memory database that can restart quickly, is more memory efficient, and benefits from the stability and resiliency of a mature, mission-critical, real-time database. In addition to the in-memory enhancements I’ve covered, we have also made improvements in our multi-tenancy, and have added developer API enhancements.
Focus on Developer API
Server 7.0 is the first of several 7.X releases focused on improving the Aerospike developer API. Developers now can index blobs, with future releases enabling indexing of all data types (including maps and lists). Another indexing enhancement is a “spend space to increase performance” by enabling the persistence of key-ordered maps.
Aerospike 7: A technical perspective
To get a more detailed technical overview of Aerospike 7, I suggest you read Ronen Botzer’s blog on the subject and join us for an office-hours webinar on Aerospike 7 to answer any questions you may have.